消息队列的消息模型
主题和队列
好的队列不是设计出来的,而是演进出来的
最初的消息队列模型
- 严格意义上的队列,数据结构中的队列
- 满足先进先出
- 要求满足严格有序
- 队列没有读操作,只有「出队」
- 多个生产者写,可消费到的信息是这些生产者生产的消息合集,每个消费者只能收到队列的一部分信息,任何一条消息只能被一个消费者收到
- 如果需要每个消费者都受到全量的消息怎么办?
- 为每个消费者单独创建一个队列,让生产者发送多份
- 方法比较蠢
- 浪费资源
- 生产者必须要知道有多少个消费者,违背了「解耦」的初衷
- 为每个消费者单独创建一个队列,让生产者发送多份
发布-订阅模型
模型图
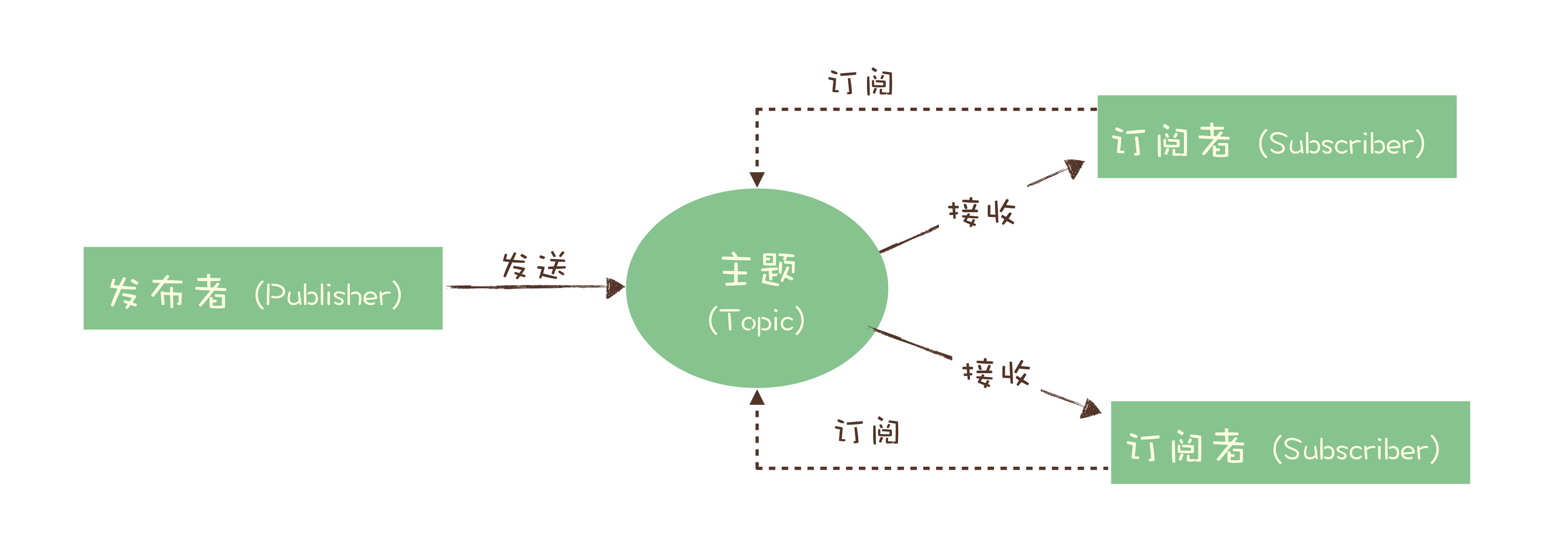
发送方被称为发布者,接收方被称为订阅者
服务端存放消息的容器叫做主题
发布者将消息发布进主题中,订阅者需要先「订阅主题」
「订阅」是一个动作,同时可以认为是主题在消费时的一个逻辑副本,每份订阅中,订阅者都可以接收到主题的所有消息
对比
- 在消息队列历史上很长时间,这两种模式是并存的,有些消息队列同时支持这两种模型,比如 ActiveMQ。
- 这两种模型,生产者就是发布者,消费者就是订阅者,队列就是主题
- 最大区别就是,一份消息数据能不能被消费多次
RabbitMQ 消息模型
坚持使用队列模型的产品之一
通过 Exchange 模块,此模块位于生产者和队列之间,生产者并不关心将消息发到哪个队列,而是将消息发送给 Exchange,由 Exchange 配置的策略来决定将消息投递到哪些队列当中
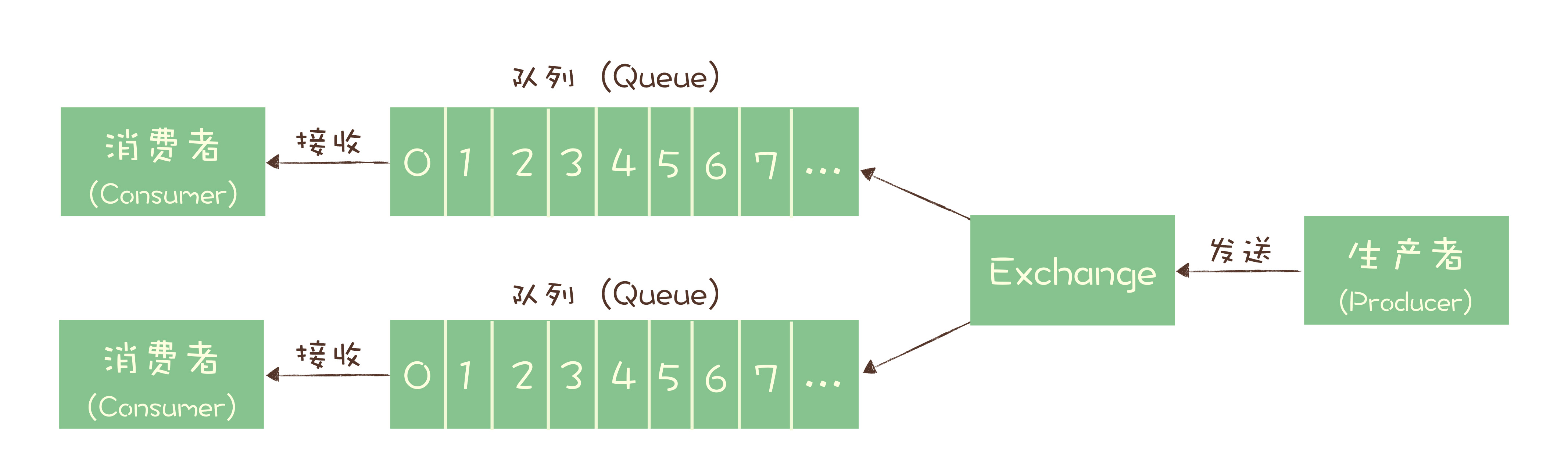
同一份消息如果需要多个消费者来消费,就需要配置 Exchange 将消息发送到多个队列,每个队列中都存在一份完整的消息数据。这样就变相的实现了发布订阅模型中的一份消息数据可以被多个订阅者来多次消费
RocketMQ 消息模型
标准的发布订阅模型
在 RocketMQ 的术语表中,生产者,消费者和主题与上面讲的发布订阅模型是完全一样的
请求-确认机制
- 生产者生产消息后,会将消息发送给服务端,也就是 Broker(中间人), 服务端将消息接受并写入队列后,会给生产者发确认的响应。如果没有得到响应,就会不断重试
- 消费者消费消息后,服务端要得到消费成功的响应,如果没有得到,也会不断发送,直到收到对应的消费成功确认
- 这个机制很好的保证了消息传递过程中的可靠性
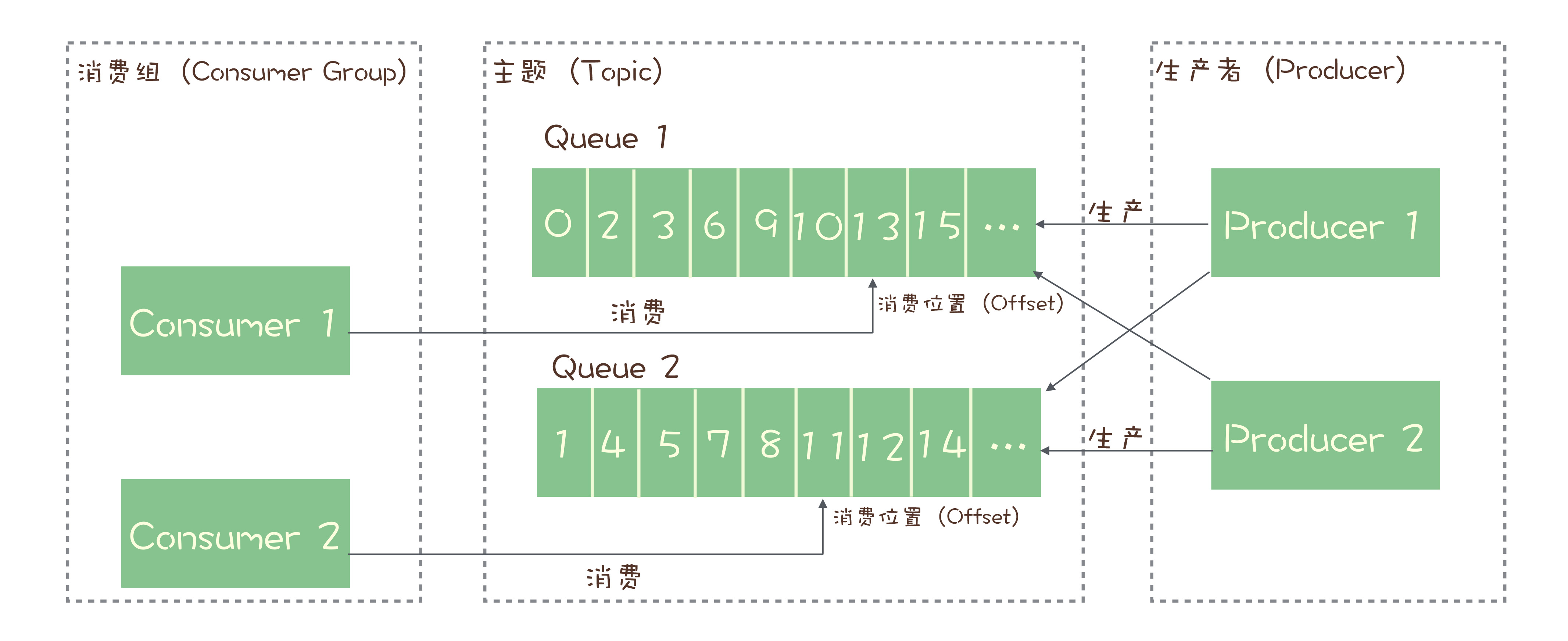
RocketMQ 中队列的概念
- 引用请求确认机制保证了可靠性,但是为了保证消息的有序性,在某一条消息被成功消费之前,下一条消息是不能消费的,否则就会出现消息空洞,违背了有序性的原则
- 任意时刻,至多只能有一个消费者实例进行消费,所以没法通过水平扩充消费者的数量来提升消费端的总体性能,为了解决这个问题,RocketMQ 增加了队列的概念
- 每个主题包含多个队列,通过多个队列来实现多实例并行生产和消费
- 只在队列上保证消息的有序性,主题层面无法保证消息的严格顺序
订阅者的概念是通过「消费组」来体现的,每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不影响。也就是说,一条消息被 Consumer Group1 消费过,也会再给 Consumer Group2 消费。
消费组包含多个消费者,同一个组内消息的消费时竞争消费关系,每个消费者负责消息组内的一部分消息,如果一条消息给 Consumer1 消费了,那么其他消费者不会收到这条消息
消费过程中,消息要被不同的组消费,所以消费完的消息不会被立刻删除。所以,RocketMQ 在每个队列上维护一个消费位置 (Consumer Offset),这个位置之前的消息都被消费过,之后的都没有。每成功一条消息,位置就加一
RocketMQ 消息模型
Kafka 消息模型
- 消息模型与 RocketMQ 完全一样
- 在 kafka 中,「队列」这个概念的名称不一样,kafka 中对应的名称是,分区 (Partition),含义和功能是没有任何区别的
总结
- 两个模型
- 发布-订阅模型
- 队列模型
- 两种消息模型没有本质区别,都可以通过一些扩展或变化相互替代
- 以上相关概念是业务层面的模型,不是实现层面。比如说 MySQL 和 Hbase 同样是支持 SQL 的数据库,它们的业务模型中,存放数据的单元都是“表”,但是在实现层面,没有哪个数据库是以二维表的方式去存储数据的,MySQL 使用 B+ 树来存储数据,而 HBase 使用的是 KV 的结构来存储。同样,像 Kafka 和 RocketMQ 的业务模型基本是一样的,并不是说他们的实现就是一样的,实际上这两个消息队列的实现是完全不同的。
- 两个模型
最后修改于 2019-12-13

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。