HDU自动AC机,八小时爬上杭电首页
前言
身为一个ACMer,整天面对电脑屏幕,一个题冥思苦想一整天,调bug调到绝望,看着自己可怜的AC数,想想都很绝望~
那么在学习之余我们也应该做一些有趣的事情,比如说 自动AC? 体验体验AC的快感,最然是假的(捂脸)
说到自动AC,我们首先想到的是什么,当然是爬虫,说到爬虫,那么就要说一说python了,没有什么语言比它更适合了.
废话不多说,先放一张战果:
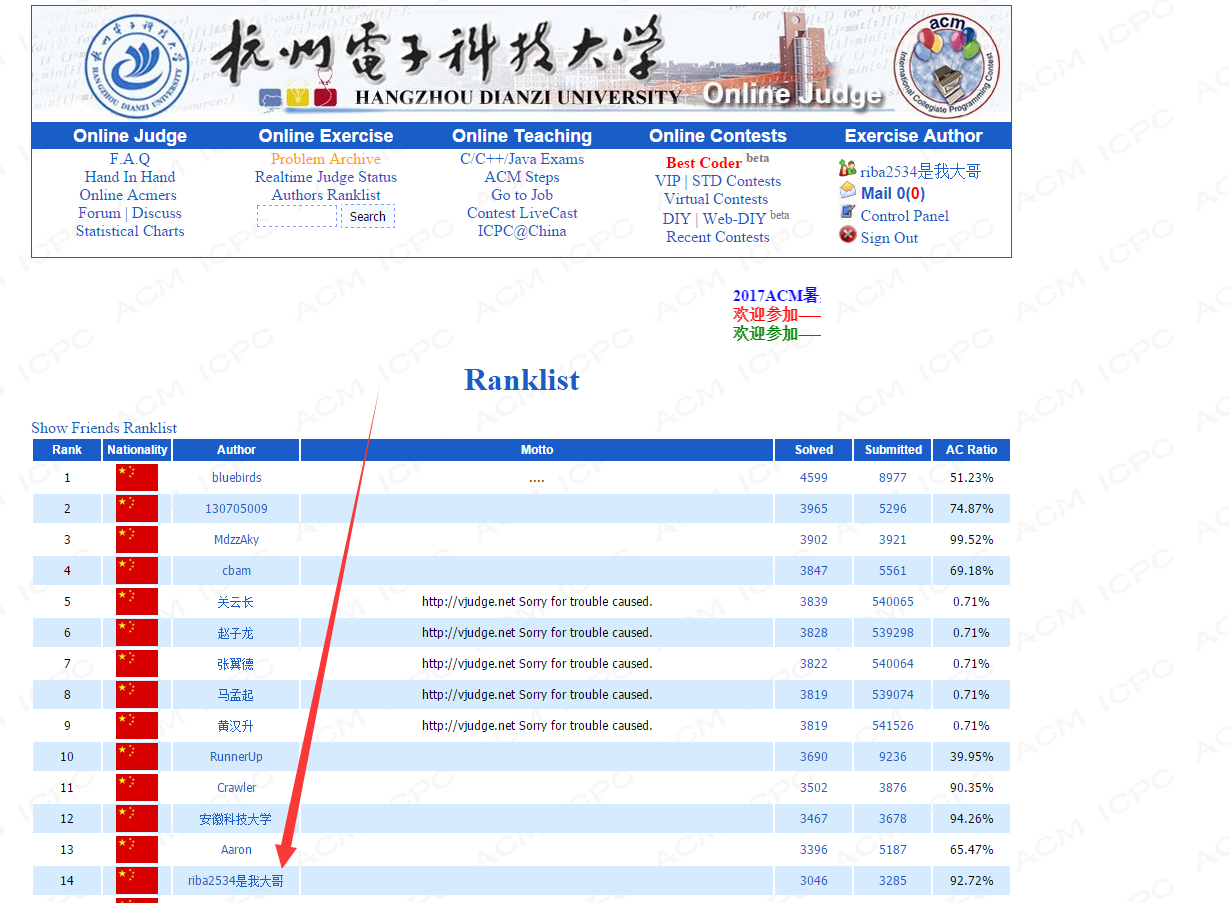

第十四名,AC率达到了百分之92,怕不怕~
工欲善其事,必先利其器,用到的工具有:
- python-3.6.2
- BeautifulSoup4 库
- requests库
那么现在,我们来说一说思路:
思路
获取
本来想好的思路是,在百度等搜索引擎,搜索hdu+题号,然后筛选出csdn和博客园的链接,然后保存提交的,但是学长给了一个网站,我发现了新大陆:
就是这个网站,上面给出了,大部分题的题解,简直是开盖即食,按捺不住这种激动的心情,那么首先,就是获取链接了:

我们点击hdoj,输入题目的ID,发现底下一排排已经AC的代码,这时,看一看网页的地址栏:
什么鬼!竟然是一堆乱码,但是我们仔细观察就知道了,这是被URL加密过的链接,我们对这个链接进行解密,结果如下:
这一次链接是不是很清晰了,里面的ID后面加数字,就是我们要搜的题目编号,我们查询的时候是需要给这个链接发GET请求就好了。
这时我们利用F12大法查看一下网页代码:

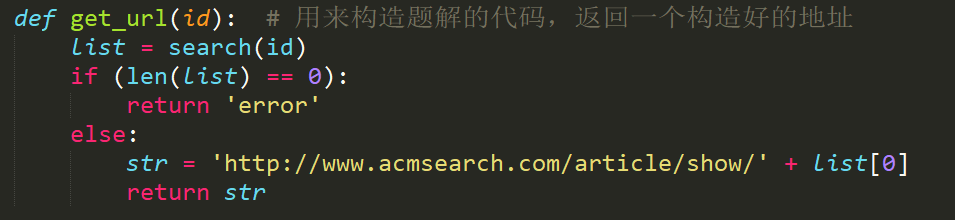
发现题解的链接都是在一个 tbody->tr->data-key 的标签里面,然后我们再构造链接:
http://www.acmsearch.com/article/show/+编号
这样就获得到了代码的页面,以HDU2111这个题来说明,我们获取了链接以后,一个GET请求发过去,会进入一个这样的页面:

没错,我们看到了AC代码,这时候我们要做的是把代码从网页中提取出来,那么我们继续查看网页源代码:
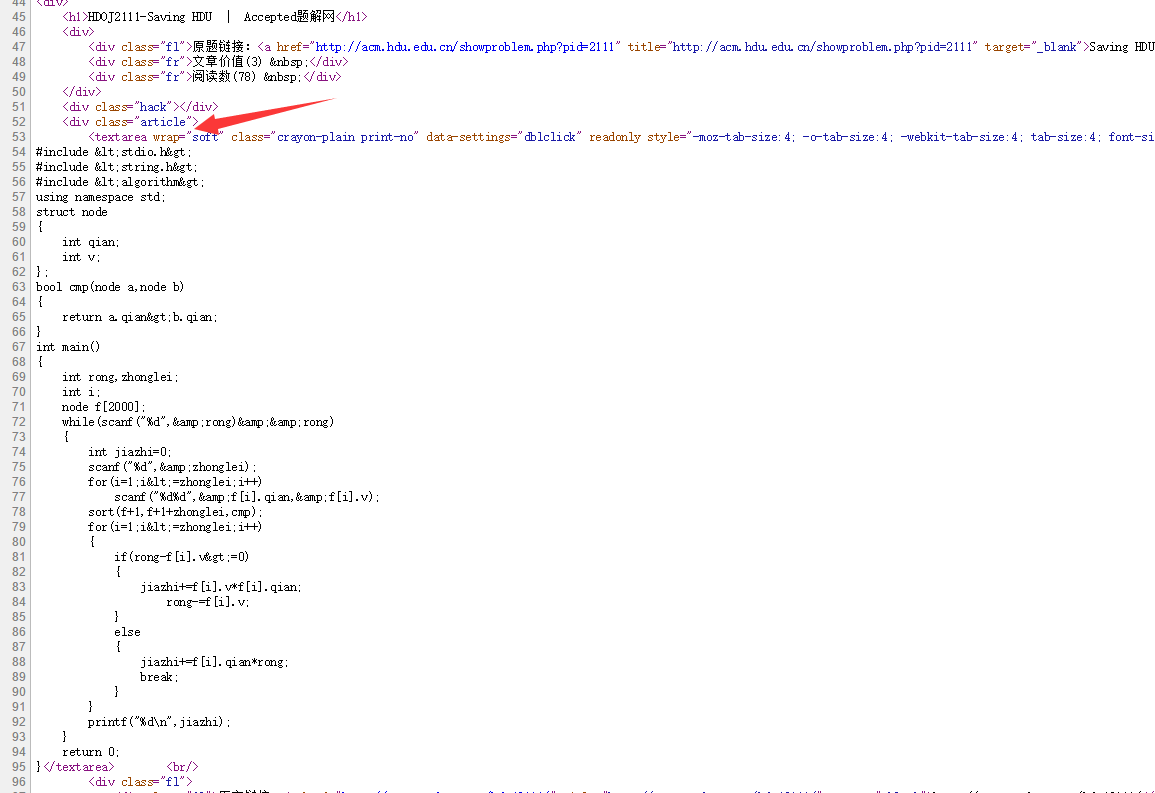
发现了啥,没错,代码就在一个标签名叫做 textarea 的标签下,我们只需要提取这个标签 里面的内容.
放一部分关键代码:

这时候,我们的代码就获取完毕了,这时候,重要的一步来了,我们要登录杭电并且提交代码
登陆HDU
我们先打开杭电首页:

我们把账号密码输进去,按F12监听数据抓包:
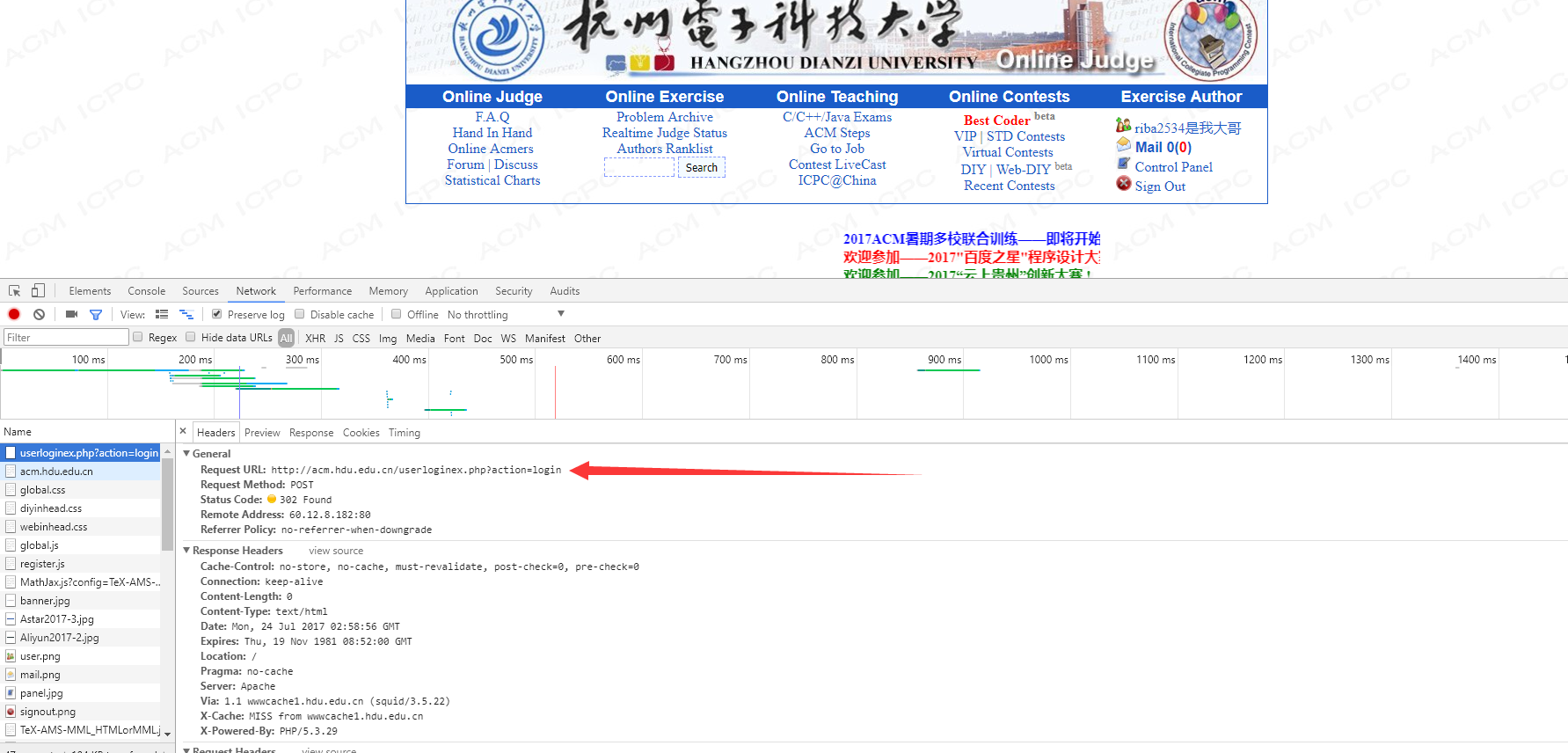
我们发现一个POST地址,这就是我们待会要登录的地址,然后看看其他发送过去的内容
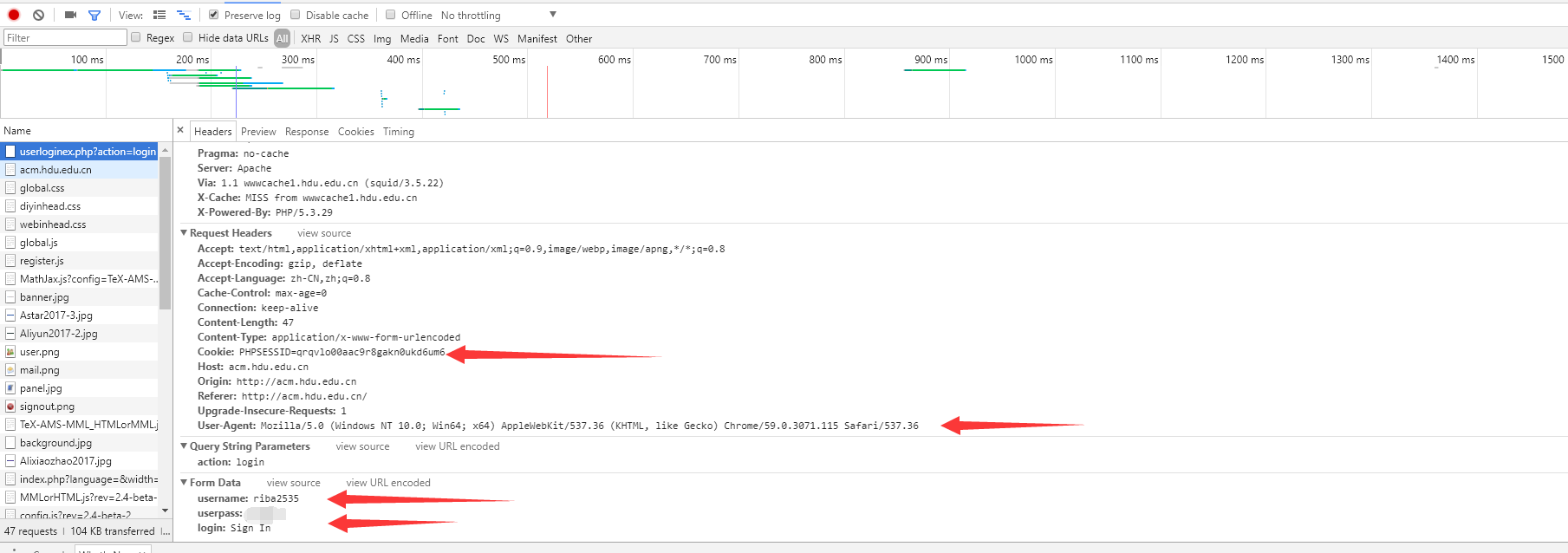
我们要发送的请求要包含:
username,userpass,login分别代表账户名,密码,操作
我们还需要带上一个User-Agent,来告诉页面我们是一个正常的浏览器访问:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36
然后我们构造请求头,和发送的数据,本来我打算用urllib库里面的cooklib对象,但是requests里面直接把cookie的事情给解决了,附上官方文档的链接:
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
这一步关键代码如下:
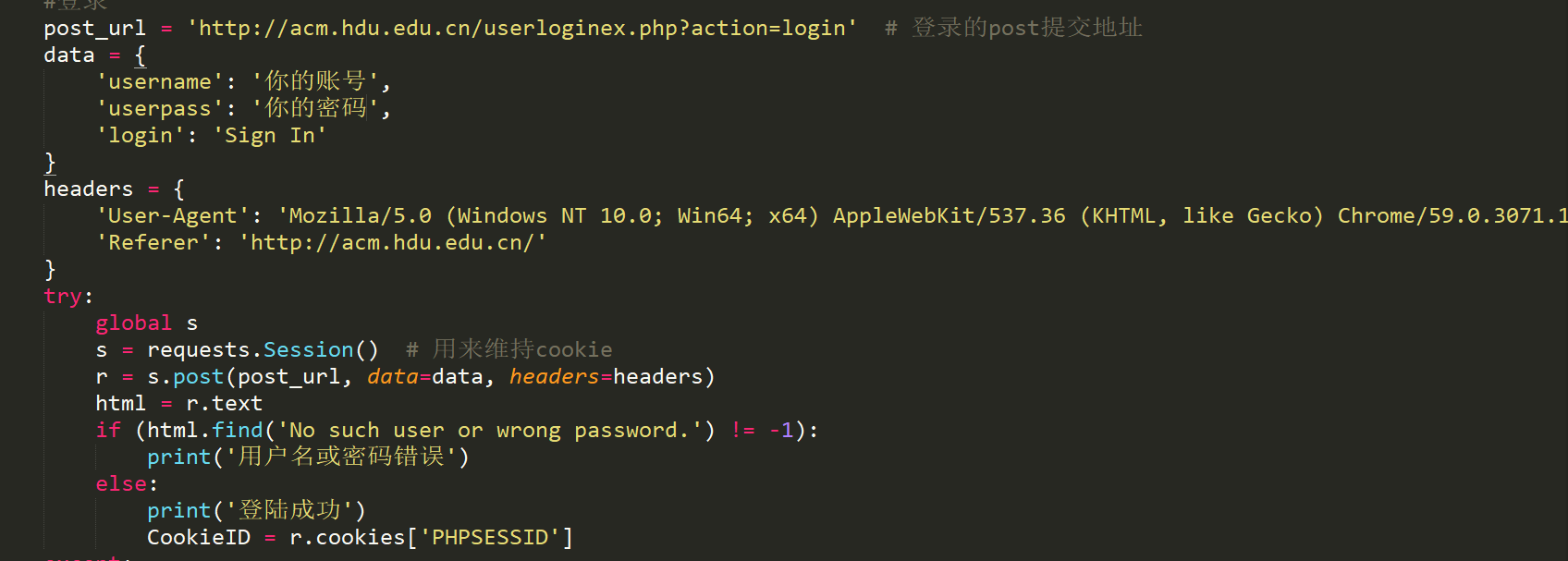
当登录成功以后,我们要做的就是提交代码了
提交
我们找一道题目,比如2111,来进行提交,首先,先抓包:
然后进行抓包:

我们得到了post地址,
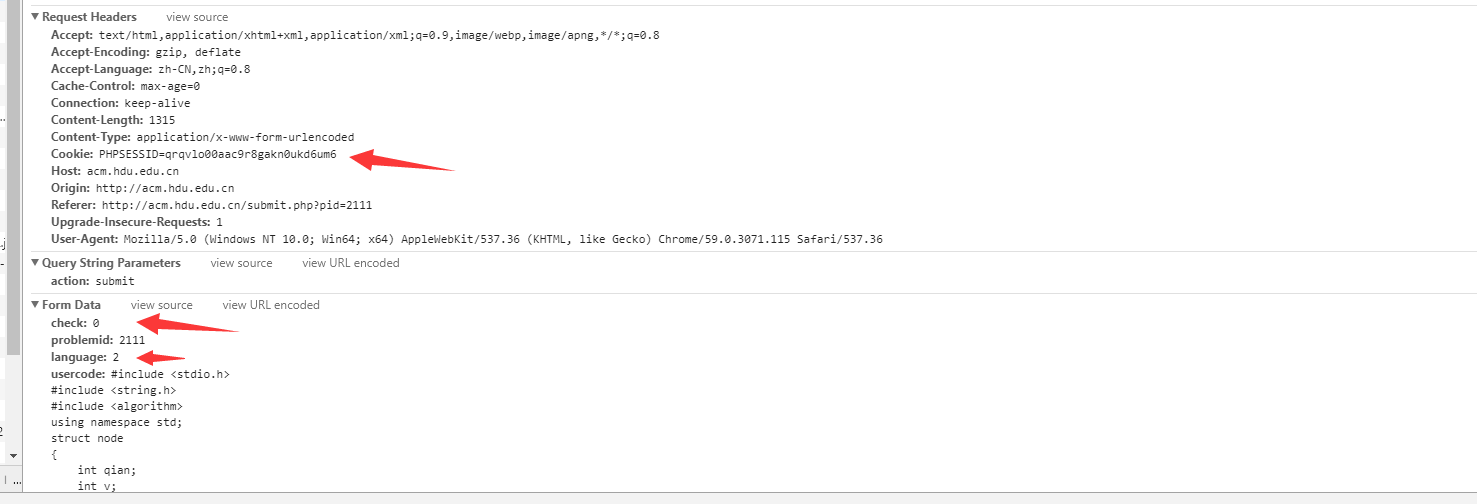
提交的时候要带上cookie,以及构造的DATA数据。
比如:
data = {
'check': '0',
'problemid': str(id),
'language': '2',
'usercode': str(code)
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': 'PHPSESSID=' + CookieID,
'Host': 'acm.hdu.edu.cn',
'Origin': 'http://acm.hdu.edu.cn',
'Referer': 'http://acm.hdu.edu.cn/submit.php?pid=' + str(id),
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
}
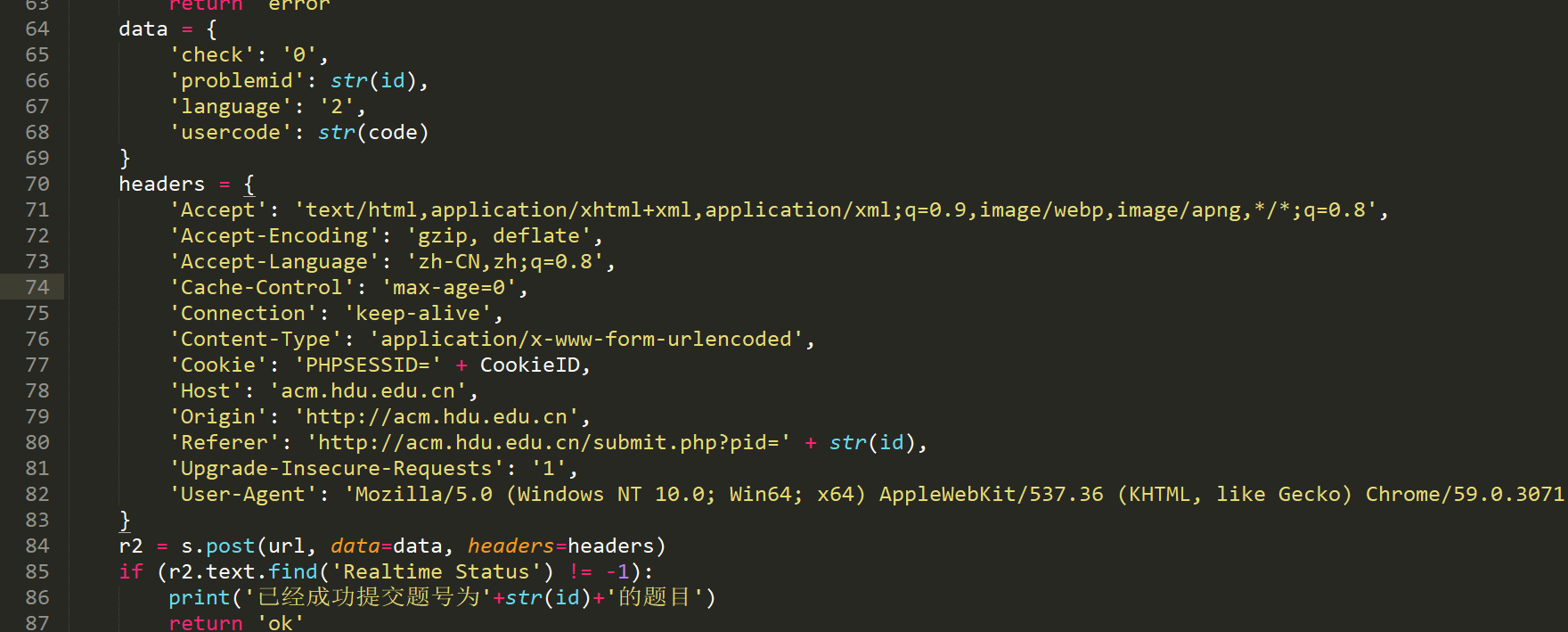
提交的关键代码如图:
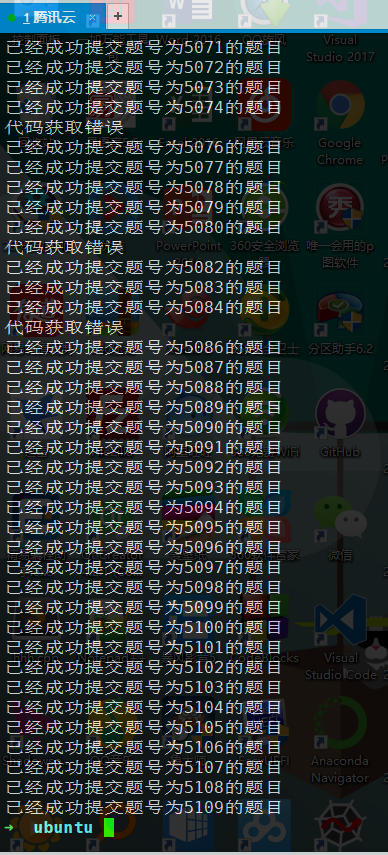
最后,当然是把爬虫上传服务器,爬上八小时,然后就进首页了~
后记
至此,关键的代码基本已经写完,剩下的就是写个循环把题号遍历一遍提交代码了,我设置的是10秒交一发,八小时AC 3000+题目,AC成功率百分之92
代码写的非常丑,还请大佬们不要见怪,由于还有很多BUG,就不放代码了,等完善以后会发在我的GitHub里面。
HDOJ需要大家爱护,所以还是不要想着搞事情。。浪费服务器资源
GitHub链接:https://github.com/riba2534/HDUautoAC
最后修改于 2017-07-24

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。